We are pleased to announce the reaching of another landmark: PetaGene’s customers have now compressed over three million genome files.
As genomic data sets continue their rapid growth, PetaGene customers across the full range of the genomic research and applications leverage PetaSuite's high compression ratios to limit their storage and infrastructure costs.
PetaGene’s software is deployed across the life sciences industry: biopharma, hospitals and research centres around the world. Our customers old and new continue to leverage our compression technology to mitigate against their rapidly rising storage costs. PetaGene’s compression software uniquely preserves all of the file data in truly lossless compression, giving our customers the guarantee that all their data is retained in a much smaller file. Additionally, our compressed files are transparently presented back in the identical original BAM/FASTQ.gz format to all tools and pipelines, which makes integration trivial and ensures compatibility with all tools. Not just storage savings: using compressed data with PetaGene’s just-in-time decompression speeds up pipelines and workflows significantly thanks to the remarkable reduction in data reads and transfers.
As genomic applications in healthcare grow it is expected that even more data will be generated and this will present a dual challenge of requiring cost-effective storage and also ensure secure, compliant data management. With that in mind, PetaGene has developed an award-winning platform to encrypt and audit all data, with bespoke region-based encryption for BAM and VCF files - the product is now in general availability. These compressed and encrypted files are compatible with all tools and, additionally, all data accesses are captured in a tamper-evident cryptographic ledger. To find out more please contact info@petagene.com.
Understanding the genomic information of a patient is key in diagnosing a plethora of genetic and rare diseases. As a result, genome sequencing approaches such as Whole Exome Sequencing (WES) and Whole Genome Sequencing (WGS) are growing in use in clinical and research laboratories such as at CH.
A critical challenge emerges as genome sequencing scales up - how to manage the increasing cost of storing these data. At CH, the volume of sequencing data is growing rapidly along with the associated storage costs. CH were looking for solutions to reduce ballooning costs of storing these data that needed to be accessed for critical research and analysis. To solve this challenge CH adopted PetaGene’s lossless compression software to tremendous effect:
“Within two months of deploying PetaGene’s compression solution, CH had made a return on investment, recovering the full cost of the PetaGene licence in storage savings. With PetaGene, we now have better control over the growth of our NGS data, allowing us to reduce storage costs while freeing up financial resources for more compute and analysis to further the research and clinical goals of CH. Hospital senior management consider the PetaGene purchase a big success.”
- Infrastructure Manager, CH
File type
# Files
Input Size (TB)
Output Size (TB)
Savings (TB)
FASTQ.gz
663,669
854
360
494 (58%)
BAM
849,465
2,165
879
1,286 (59%)
Total
1,513,134
3,019
1,239
1,780 (59%)
“Deploying PetaGene at CH was a straightforward process. Our users do not have to modify any of their tools or workflows since PetaGene’s decompression library transparently serves original uncompressed data to the tools/pipelines. Since users are essentially able to work with the original data except that the data is more than 50% smaller, there are additional benefits such as faster data transfer speeds and analysis times.”
Recently our co-founder Vaughan Wittorff and Phil Sweeney from Dell Technologies sat down to discuss how the use of Next-Generation Sequencing is expanding as the costs are coming down, creating an explosion of NGS processing and resulting data.
Find out how PetaGene can address the demands of that scale of data, in a two-part Dell Healthcare PowerChat podcast.
In Part Two (which we recommend you listen to first), Vaughan recaps and completes his review of PetaGene’s capabilities in addressing NGS data challenges and outlines PetaGene’s product set.
Phil discusses PetaGene and Dell’s partnership and Vaughan shares customer success stories.
Click here to listen to the podcast:
(no account required)
In Part One, (which we recommend you listen to second), Phil gives a refresher on NGS and describes some new NGS use cases, and Vaughan describes how he sees NGS evolving in terms of use cases.
Phil then discusses the components of successful NGS Processing. Phil outlines the challenges associated with managing NGS data and Vaughan begins to describe how PetaGene responds to those challenges.
Click here to listen to the podcast:
(no account required)
HISAT2 (Hierarchical Indexing for Spliced Alignment of Transcripts 2) is a graph-based read mapping tool for both DNA and RNA sequences.
HISAT2 enables a fast search through its graph index, mapping reads to the entire human genome along with a large number of variants. Since it is a widely used tool, at PetaGene we have added it to our test suite to ensure our compressed files and transparent decompression technology work optimally with HISAT2.
In this blog post we demonstrate the compatibility of PetaGene software with HISAT2, showing benefits such as faster transfer and shorter analysis times as a result of working with compressed data.
PetaGene’s compression software, PetaSuite, is used to losslessly compress FASTQ.gz and BAM files. The compressed files are between 60%–90% smaller, helping our customers save on storage costs and store more samples per petabyte of storage space.
In addition, PetaSuite comes with a user-mode library called PetaLink that transparently handles file decompression on-the-fly. This allows tools to interact with the compressed files via a virtual file so they see only the original, uncompressed data. There is, therefore, no need to modify any tools or pipelines, and there is also no need to decompress the files before use. PetaLink allows for fast random access into the file while performing transparent just-in-time decompression. Thus, PetaLink ensures that PetaGene compressed files are interoperable with existing tools and workflows.
Furthermore, users can connect their cloud/object storage buckets using the pgman utility, and PetaLink reads these cloud paths as if they are local filesystem paths. This means that, thanks to PetaLink and pgman, all tools and workflows work seamlessly with cloud paths for both reading and writing.
To test HISAT2 with PetaGene’s software, we losslessly compressed paired, FASTQ.gz reads from an RNA-seq experiment using PetaSuite Cloud Edition (CE). PetaSuite CE is able to write files directly to cloud storage. In this example, the files are compressed and streamed directly to an AWS S3 bucket created for this study.
$ time petasuite --compress --md5match --validation md5full \ --species auto ERR1138635_1.fastq.gz ERR1138635_2.fastq.gz \ --dstpath s3://demo_hisat/hisat2_testfiles/compressed
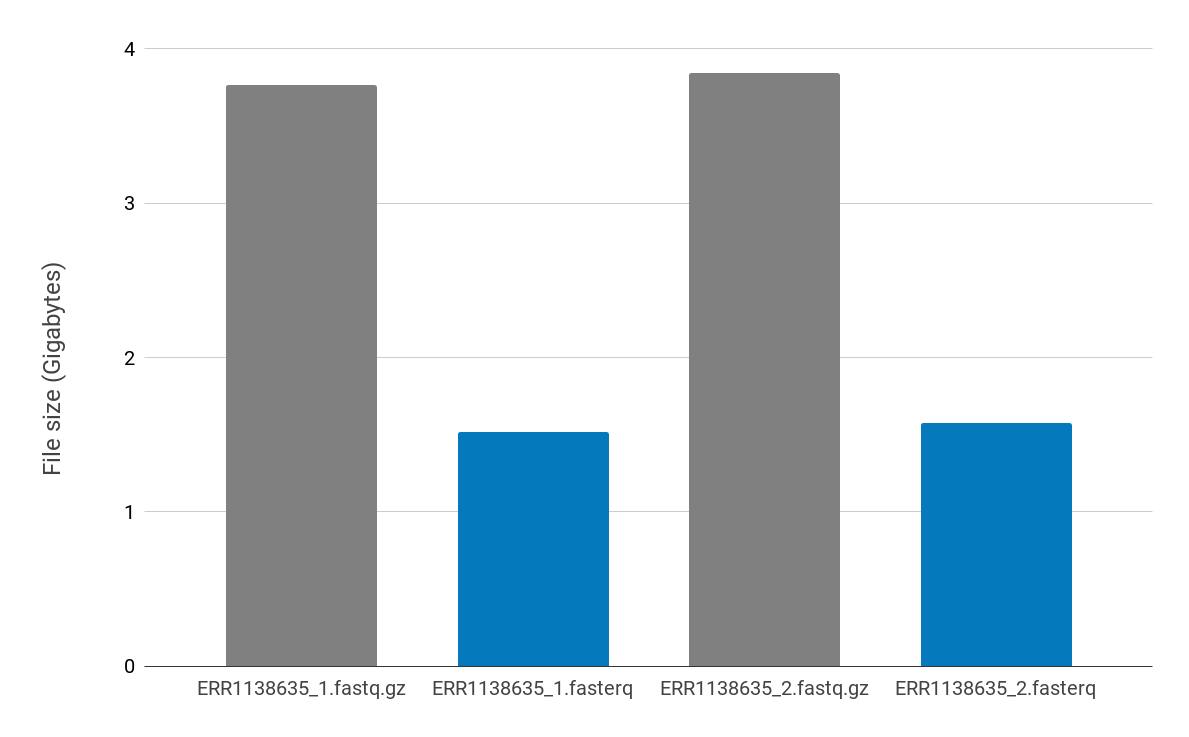
Figure 1. Comparison of file sizes after gzip compression (grey) and after PetaSuite compression (blue) for paired FASTQ files. The PetaSuite-compressed files are 60% smaller than the original gzipped files.
The PetaSuite compressed data are used as the input into HISAT2. To do this the PetaLink decompression library needs to be loaded. PetaLink transparently handles decompression of the compressed files, serving original uncompressed data to HISAT2. With the PetaLink library loaded, virtual, uncompressed files are inserted into the filesystem (shown below in blue). These virtual files look and behave exactly as the original uncompressed file would, but the virtual files do not consume any inode resources.
By default, we present virtual files as FASTQ.gz files. However, HISAT2 takes unzipped FASTQ files as the input, normally performing an unzip step if a FASTQ.gz file is used. With PetaSuite-compressed files, it is possible to have each compressed file presented back as multiple different virtual files by simply setting an environment variable. Below, we set the environment variable to generate a virtual FASTQ file. Thus one FASTERQ file can be presented as multiple different virtual files.
Compressing files using PetaGene’s technology offers a number of benefits. The smaller size means the cost of storing the data is lower. Additionally, transferring the data between storage and computing nodes is faster, reducing I/O bottlenecks. Furthermore, PetaLink ensures transparent, fast access of compressed data to existing tools and workflows without any modifications.
Here, we carried out a series of benchmarks showing that HISAT2 works with our compressed files and the transparent decompression library, giving performance improvements in the speed of transfer and analysis.
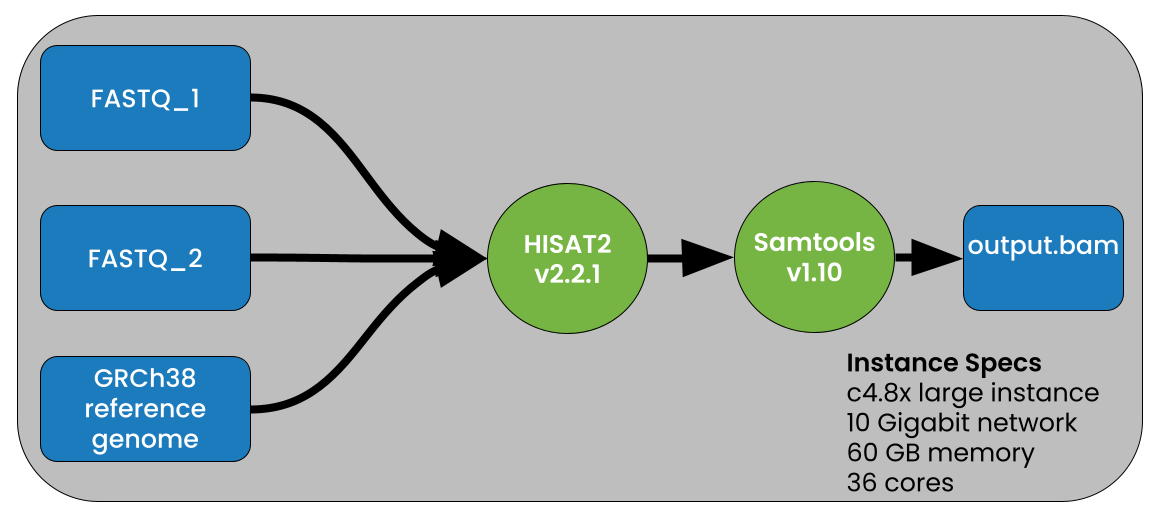
To test the performance gains when using compressed vs uncompressed data we used the pipeline shown in Figure 2.
Figure 2. The analysis pipeline used HISAT2 (v2.2.1) and samtools (v1.10) to align paired FASTQ files with the HISAT2 indexed reference genome. HISAT2 was run with the following command line: hisat2 -x grch38/genome -p 8 -q -1 FASTQ_1 -2 FASTQ_2 | samtools sort -@ 8 -O BAM -o output.bam (HISAT2 and samtools were run with 8 threads).
Results
1. PetaGene-compressed files transparently work with HISAT2.
This demo shows that PetaGene compressed files can be used as input into HISAT2 using the PetaLink library to perform transparent decompression to serve original, uncompressed data to HISAT2. The subsequent output data is in the SAM format, and so, to generate a BAM file, we piped the output to samtools (samtools sort -@ 8 -O BAM -o output.bam) as shown in Figure 2.
2. Runtime is shorter when using PetaGene compressed files.
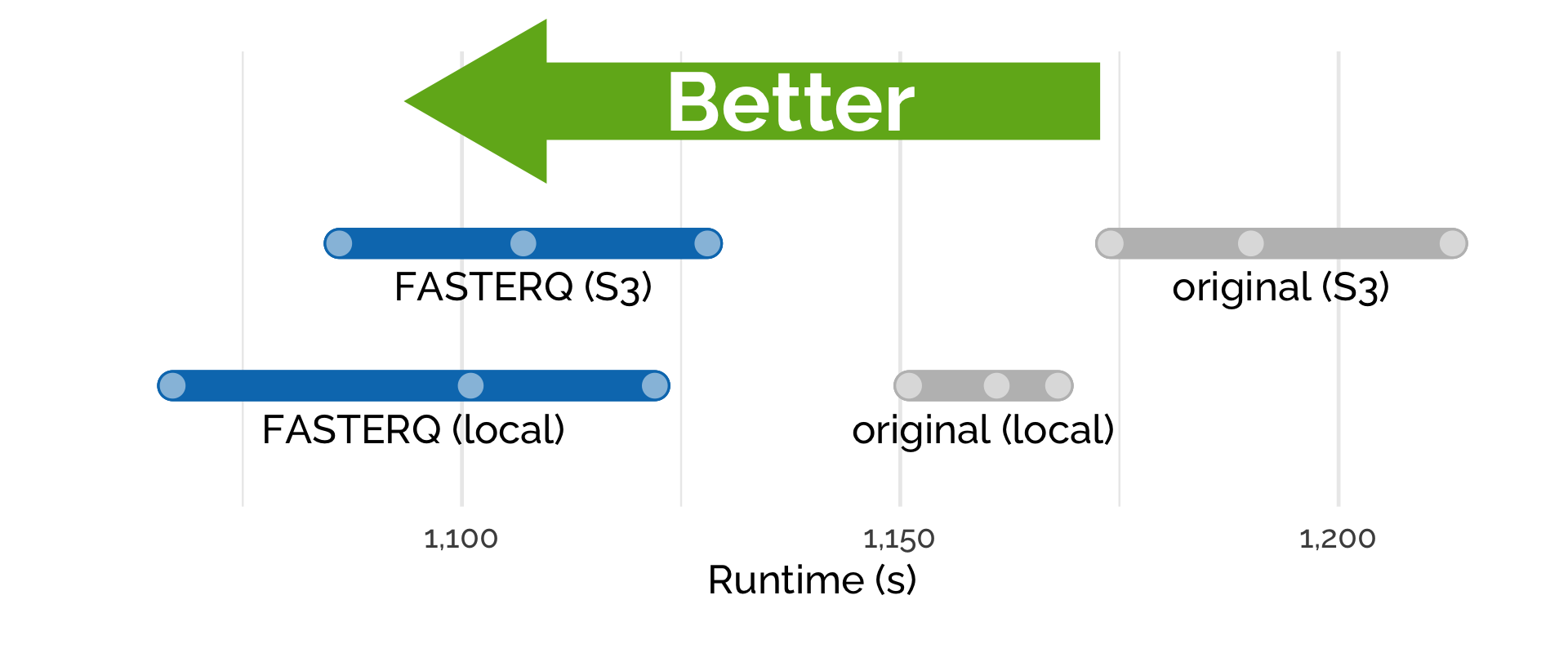
When executing the pipeline, we measured the time it took to process the samples when the data was stored locally on the instance or by directly streaming the data from S3 (Figure 3). In both scenarios, using compressed files sped up the analysis with shorter runtimes recorded. Importantly, PetaLink Cloud Edition carries out transparent, just-in-time decompression and allows streaming data directly from S3.
3. Streaming directly from the cloud removes the need for local storage on the instance.
By streaming the data directly from S3 using PetaLink, we didn’t need to attach large storage to the compute instance.
4. PetaLink allows HISAT2 to take input files that are stored in the cloud.
Furthermore, PetaLink enables HISAT2 to work with data stored in cloud/object storage (AWS, GCP, Azure and any S3-compliant object storage) without any need to modify HISAT2.
Figure 3. Compressed files have a shorter runtime than the original data independent of whether the files are stored locally on the instance or in cloud/object storage (S3).
PetaLink technology enables:
Cloud-enabling technology — allowing tools to natively work with data stored in the cloud.
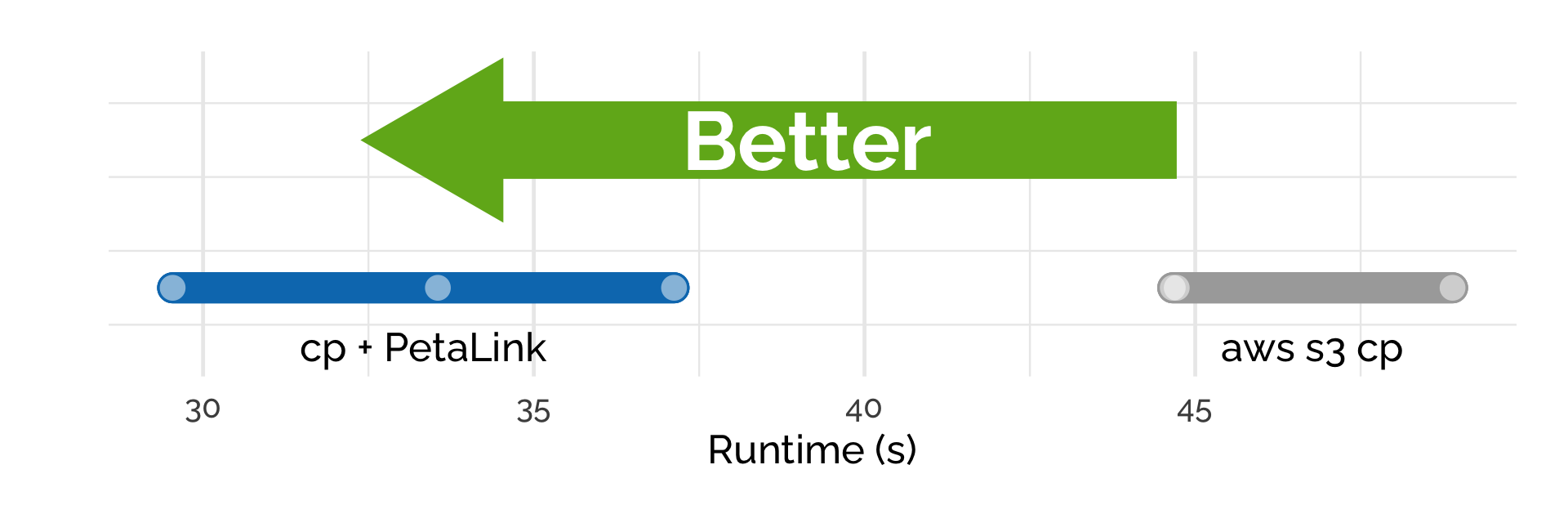
With the PetaLink library loaded, standard cp can be used to copy files directly from cloud storage to the instance. Here we copied the paired, FASTQ.qz files (7.62 GB) from S3 to the C4.8x large instance, which has a 10 gigabit network connection. We used the standard Linux cp binary and the aws s3 cp command-line tool.
High-speed transfer of data
Using cp + PetaLink saw a speedup of 40% on average, with the average speed of transfer 1.85 Gbps compared to 1.32 Gbps for aws s3 cp.
Figure 4. PetaLink enables the standard Linux cp to download the paired FASTQ.gz files (7.62 GB) directly from cloud storage and is faster than AWS S3 cp.
Summary
PetaGene offers bioinformatics users lossless compression software that helps to reduce storage costs and accelerate data transfer and analysis.
PetaGene reduced the storage costs by 60%, reduced the transfer time for uncompressed data by 40%, reduced the transfer time for compressed data by 76%, and reduced the analysis time by about 7%.
Using our PetaLink library, decompression of the files is handled transparently, meaning that compressed files can be used for day-to-day analysis as PetaLink ensures that all tools and applications see original, uncompressed data. The analysis runs faster when the compressed data is used as input in this way.
PetaLink Cloud has additional features: users are able to pair public as well as private cloud storage buckets, and access cloud paths as if they were local filesystem paths.
Standard Linux tools and other binaries are able to work with cloud paths when PetaLink is enabled. Here we described how the standard Linux cp command works with cloud paths, and that the transfer is accelerated when compared with the AWS CLI copy tool.
Furthermore, HISAT2 is able to read input files located in the cloud. This means users avoid the need to first download the data to an instance. It also reduces the amount of storage space required on an instance and allows users to directly stream data from the cloud.
Overall, at PetaGene we have architected our compression solution to ensure data integrity, interoperability with all tools and pipelines through transparent decompression, and support for cloud storage to help reduce costs of cloud computing.
Sample files were downloaded from ENA, and the HISAT2 genome references were copied from the AWS Registry for Open Data.
Some additional information about the samples used in this analysis:
Illumina HiSeq 2500 paired-end sequencing;
RNA-seq of liver tissue and liver cancer cell lines
For PetaGene, the one million genome era is underway
We are pleased to announce the reaching of a landmark: PetaGene’s customers have now compressed over one million genome files.
The dramatic drop in the cost of sequencing genomes and the numerous applications of this data to tackle critical diseases such as cancer and rare diseases has led to the rapid growth in genomic data.
PetaGene’s software is deployed across the life sciences industry: biopharma, hospitals and research centres around the world. Our customers adopted our compression technology to mitigate against the rapidly rising storage costs. PetaGene’s compression software uniquely preserves all of the file data in truly lossless compression, giving our customers the guarantee that all their data is retained in a much smaller file. Additionally, our compressed files are transparently presented back in the identical original BAM/FASTQ.gz format to all tools and pipelines, which makes integration trivial and ensures compatibility with all tools. Using the compressed data with PetaGene’s just-in-time decompression in this way actually speeds up pipelines and workflows significantly.
As genomic applications in healthcare grow it is expected that even more data will be generated and this will present a dual challenge of requiring cost-effective storage and also ensure secure, compliant data management. With that in mind, PetaGene has developed an award-winning platform to encrypt and audit all data, with bespoke region-based encryption for BAM and VCF files - the product is now in general availability. These compressed and encrypted files are compatible with all tools and, additionally, all data accesses are captured in a tamper-evident cryptographic ledger. To find out more please contact info@petagene.com.
Genome UK is an exciting and ambitious new strategy that builds upon the UK's world-leading excellence in genomics to build "the most advanced genomic healthcare system in the world". We applaud this initiative, and believe this will enable the NHS to leverage precision medicine to improve outcomes and reduce costs, significantly drive research into new treatments and diagnostics, as well as foster an ecosystem for the UK Genomics Industry to thrive.
However, this is all contingent on getting the execution right, and we have seen past ambitious genomics projects suffer due to what are "Bio-IT" issues, that is IT problems with practically handling biological datasets. Due to the scope of this initiative, and having had a great deal of experience addressing issues in this domain, we have some recommendations for how to prevent some foreseeable problems, and to make it a real success.
Our recommendations cover key issues in:
data security and privacy, including regional encryption and data minimisation
reducing technical barriers to ensure efficient IT and lower costs
the need for computational reproducibility, and supporting existing pipelines
PetaGene and NVIDIA announce seamless integration of PetaGene’s PetaSuite tools as a standard part of NVIDIA Clara Parabricks Pipelines. PetaGene’s transparent compression reduces file sizes by 60-90%, and enables Parabricks Pipelines GPU-accelerated genome analysis to run 29% faster.
Cambridge, UK, Oct. 6, 2020: PetaGene and NVIDIA today announce their integrated bioinformatics solution to accelerate genomic analysis and simultaneously reduce data storage. PetaGene’s PetaSuite software decreases the size of genomic data and is integrated into NVIDIA Clara™ Parabricks Pipelines, a GPU-accelerated tool for accurate genomic data analysis. This technology combination now allows scientists and clinicians to access PetaGene’s genomic compression software within Parabricks Pipelines compute framework. FASTQ.gz and BAM files compressed by PetaGene’s PetaSuite software within Parabricks Pipelines compute framework or elsewhere can now be analyzed directly with Parabricks Pipelines.
PetaGene and Parabricks clear choices for TGen
The Translational Genomics Research Institute (TGen), a nonprofit medical research institute that is examining the genetic components of common and complex diseases, has confirmed faster end-to-end analysis when using PetaGene-compressed files within Parabricks Pipelines. TGen confirmed that the transparent readback of the compressed files using PetaGene’s user-mode library is now fully compatible with the Parabricks Pipelines environment. Sequencing and compute costs have plummeted, but storage costs have not. With Petagene and GPU-powered Parabricks Pipelines, genomic analyses can be run faster, and with significant cost savings on storage and compute.
“At TGen, we have a long history of working with a large number of bulky genomic files. As our workflows mature and scale, we have been keen to build our genomics infrastructure from the ground up with the most efficient tools and systems available.” said Dr Glen Otero, VP of Scientific Computing at TGen. “PetaGene and NVIDIA Clara Parabricks Pipelines were independently clear choices for us. Having them interoperable like this is important, and the fact that the combination further accelerates the aggregate performance is fantastic.”
PetaGene gives 29% speedup to Parabricks Pipelines without added complexity
TGen’s benchmarking showed that germline workflows in Parabricks Pipelines run 29% faster with PetaGene-compressed data than with regular genomics files, and generate identical results. This significant speedup is due to the behind-the-scenes I/O savings from PetaGene’s PetaLink user-mode library as it does just-in-time decompression. Since this library creates virtual FASTQ.gz and BAM files, users of the compressed files never need to interact directly with the compressed files - the virtual files are fully compatible with all existing tools and pipelines. Besides PetaGene’s compressed data, Parabricks GPU-accelerated analysis workflow is a clear differentiator compared to CPU-based workflows. GPUs save on overall space and operational costs as it requires fewer GPU servers than CPU servers to run the same analyses.
NVIDIA Clara Parabricks Product Manager Tim Harkins, Ph.D. commented, “Many scientists and clinicians are working hard to identify those genetic variants that contribute to health and diseases, ultimately providing better therapeutic choices for patients. The amount of data generated on a per individual genome is significant and all trends are pointing to more growth. The compression technologies from Petagene are going to save the community a significant amount in data storage, and by integrating with Parabricks Pipelines, the amount of time saved will be of an equal contribution.”
Dr Vaughan Wittorff, Co-Founder and Chief Commercial Officer of PetaGene said: “GPU-Powered NVIDIA Clara Parabricks Pipelines appeals to customers who want the fastest analysis speeds for genomics, and those kinds of customers also want the most efficient storage techniques without having to change anything they do and without vendor lock-in. Integrating PetaGene tools with NVIDIA’s genomic tools was therefore very natural. The fact that PetaGene’s transparent compression also makes Clara Parabricks even faster is great for everyone.”
Joint free trial of Parabricks and PetaGene available today
Get Started today. NVIDIA and PetaGene provide a FREE 30-day license to NVIDIA Clara Parabricks which comes with a free trial of PetaGene’s PetaSuite tools to do compression and transparent readback.
About PetaGene
PetaGene was founded in Cambridge, the birthplace of genomics, to address the rapidly growing data management problems of the genomics industry. PetaGene’s software enables compression of huge amounts of genomic data without compromising on access or data quality. The company’s products go beyond regular data reduction techniques and have three times been recognized by Bio-IT World’s Best of Show Award for their industry-leading performance and usability. For more information visit https://petagene.com or e-mail sales@petagene.com.
Genomic data files, whether BAM or FASTQ.gz format, are large and make huge demands on IT infrastructure. But, how can you tell if the challenges you face can be solved by compressing your genomic data with PetaGene technology? Here’s a list of six scenarios where lossless compression with transparent read-back will help.
1. Your storage systems are nearing capacity
PetaGene compression transparently multiplies your existing storage capacity by between 2.5x and 11x. You don’t need any scratch space when using the compressed data.
2. You want to move data to public clouds
PetaGene tools allow painless bulk or incremental migration to the cloud, and compressed data can be randomly accessed and streamed directly from object storage as if they were regular files.
3. Your cloud storage/egress bills are out of control
PetaGene compression will reduce both of these bills by 60-91%.
4. You need to archive data but want to maintain access
With PetaGene compression you can keep all your data in hot storage, for the same overall cost as keeping it uncompressed in cold storage and accessing it infrequently.
5. Data transfers are a bottleneck to your analysis pipelines
When your pipelines are I/O bound, PetaGene compression typically speeds them up by 2-3x.
6. You would like to recover budget from storage for more research
If you are experiencing any of these issues, just hit the ‘Free trial’ button at the top of this page to ask for a free Software Evaluation package, or click here.
PetaGene’s PetaSuite compression software and cloud-computing solutions speed up data transfers and reduce storage costs for research projects involving genomics data.
We are pleased to announce that Astrazeneca has selected PetaSuite software to compress the genomics data sets for AstraZeneca’s Centre for Genomics Research (CGR). Using genomics data and state-of-the-art methods for genomic analysis, the CGR investigates underlying genetic causes of disease and aims to integrate genomics across the company’s drug discovery platform. PetaSuite accelerates data transfers for cloud computing and reduces storage costs for any research project involving genomics data.
“Using genomic data for biopharmaceutical targets discovery requires large cohorts with massive multi-petabyte data sets. The time required to transfer these data from sequencers to compute clusters as well as the cost of storage can cripple these large initiatives,” said Vaughan Wittorff, Ph.D., Co-founder and Chief Commercial Officer of PetaGene. “PetaSuite addresses the challenges caused by growing volumes of genomics data and achieves up to 10x reductions in storage costs and transfer times, while adhering to the industry-standard BAM and FASTQ genomics file formats.”
More than 200,000 files processed
To date, AstraZeneca’s CGR has processed more than 200,000 genomics datasets, generating over a petabyte of data. One petabyte of data is equivalent to streaming HD movies for 40 years without a break. At this volume of data, problems in processing time, data transfers and storage size can impact the ability to deliver at scale. PetaGene’s compression software will enable the CGR to compress over 200,000 BAM files in a 24-hour period and will add the compressed data to tiered cloud storage.
Average data size reduction of 76%
“AstraZeneca’s Centre for Genomics Research has the bold ambition to analyse up to two million genomes by 2026. Minimizing the storage footprint and transfer time of genome data while maximizing data access and compute processing is a necessity to enable us to achieve our ambition.” said Slavé Petrovski, Vice President and Head of Genome Analytics and Bioinformatics, Discovery Sciences, R&D, AstraZeneca.
PetaSuite will enable the CGR to achieve an average data reduction of 76% or a 4x expansion of storage capacity. PetaGene’s transparent, lossless compression of files reduces transfer times to less than a quarter, and PetaGene’s software allows unmodified analysis tools to run more quickly.
PetaSuite users typically make it an intrinsic part of their cloud or locally hosted analysis pipeline. As data is processed, it is compressed ready for use in the next stage of analysis without it needing to be decompressed later. PetaSuite Cloud Edition allows for the seamless integration of an organization’s own tools and pipelines in the cloud or local environment of their choosing.
Read more
Click here to read the far-reaching GenomeWeb article of 31st October 2019 about PetaGene which includes this news about AstraZeneca (requires premium subscription).
We are pleased to announce that Princess Máxima Center for Pediatric Oncology, the largest pediatric cancer center in Europe, has chosen to use PetaGene’s transparent, lossless genomic data compression software, called PetaSuite, to reduce its data storage costs while accelerating access to the data. Next-generation sequencing plays an integral role in the Center’s diagnostics and research discoveries. These valuable genomic datasets are large, and their volumes are growing. As such the Center sought to find a compression technology that can store genomic data for longer at a much lower cost while removing bottlenecks in genomic sequence analysis.
PetaGene's PetaSuite software was evaluated by the Center against other compression techniques and unlike these, PetaSuite met and exceeded the criteria for a simple to implement and high compression performance solution, supported to a commercial standard.
Positive evaluation results
Senior Principal Investigator Dr. Patrick Kemmeren at the Princess Máxima Center describing the process, said: “Our tests with PetaGene’s compression software gave very positive results. We tested whole exome samples, RNA-Seq and whole genome sequencing data for different tumor samples. Implementing the software on our high-performance compute cluster is easy, the compression ratios are larger than what we obtain compared to CRAM compression, and accessing data is actually slightly faster compared to non-compressed BAM files. This on top of the added benefits of not having to switch to a different file format, a perpetual license for decompression and the time gains in not doing the BAM to CRAM conversion/retooling (and vice versa for some tools). As a result, we decided to implement PetaGene’s compression software within our computational infrastructure."
The right software at the right time
Jos Leendertse, Manager Research IDT at Princess Máxima Center, commented “By implementing PetaGene’s compression software we are also able to speed up the migration process to our new storage infrastructure. It’s not only the right software but also at the right time.”
Vaughan Wittorff, Ph.D., Cofounder and Chief Commercial Officer at PetaGene added, “During the evaluation process, the researchers found PetaSuite’s transparent access technology particularly compelling since it meant that the compressed data could integrate seamlessly with the bioinformatics structure Princess Máxima Center already had in place. A key challenge with compression is to ensure that end-users can continue working with the compressed files without having to change their existing, optimised workflows. PetaGene has solved this by ensuring that the compressed files are readable to existing tools and pipelines in the compressed state. This means our customers do not have to change any of their tools and pipelines, making it easy to integrate our compression technology within their infrastructure.”
About Princess Máxima Center for Pediatric Oncology
Opened in 2018, the Princess Máxima Center for Pediatric Oncology, based in Utrecht, The Netherlands, consolidated the work of seven different academic centers across the Netherlands into the largest pediatric cancer center in Europe. As both a hospital and a research institute, the Center has a combination of world-class facilities, leading clinicians and researchers all driven by a passion to cure pediatric cancers. By integrating the research facilities with the hospital, the Center is better equipped to implement novel discoveries into clinical care. For more information, visit www.prinsesmaximacentrum.nl/en.